Pequeño panorama de la Inteligencia Artificial
Resumen
El objetivo de este ensayo es dar una pequeña introducción a la Inteligencia Artificial. Trata de presentarla como un trabajo colectivo humano en el que existen diversas posturas y críticas. También explica la tendencia actual en la investigación y algunos de sus logros. Asimismo, expone uno de sus grandes beneficios y los peligros en el corto y mediano plazo que acechan a la humanidad. Este ensayo concluye con algunas notas y lecturas sugeridas.
1 Introducción
La inteligencia es un concepto difícil de definir concretamente y, en consecuencia, comúnmente malentendido y antropoformizado por las personas. Por ejemplo, podríamos considerar como genio a una persona que realiza cálculos mentales más rápido que otra haciendo lo mismo con una calculadora electrónica. Sin embargo, la inteligencia de esta calculadora humana se ve opacada junto a un físico teórico cuyas habilidades creativas y dominio e intuición matemática lo llevan a proponer teorías de cómo se creó el universo. Por otro lado, jugadores profesionales de fútbol como Neymar son catalogados como genios y no es para menos. Contradictoriamente a lo que se podría pensar, un estudio indica que la diferencia entre un jugador de su talla y uno amateur radica en que ellos presentan una actividad cerebral 10 por ciento más baja [1]. Lo que sugiere que gracias a esto sus tiempos de reacción son más rápidos por ser casi automáticos. Además, el movimiento per se de tenistas como Andre Agassi forman una memoria que desaparece con el paso del tiempo.
La inteligencia no es una característica propia de los seres humanos, sino que está presente en los animales, mecanismos de la naturaleza y puede venir de diferentes formas. Por ejemplo, una colonia de hormigas puede ser considerada como una inteligencia colectiva y superior a sus individuos [2]. Hay quienes incluso llaman al rastro de feromonas dejado por las hormigas para encontrar alimentos como una memoria[3]. Por otra parte, la evolución ha provisto de mecanismos inteligentes a diversos animales para engañar a su depredador o presa. Un caso familiar a nosotros son los animales domésticos como los perros. Lo que nosotros podemos entender como sentimiento de culpa en sus caras cuando son reprendido es en realidad una mentira ya que ellos no pueden experimentar tal sentimiento sino miedo [4].
De acuerdo a Wikipedia[5], la inteligencia “se ha definido de muchas maneras en términos de capacidad lógica, pensamiento abstracto, entendimiento, auto-conciencia, comunicación, aprendizaje, conocimiento emocional, memoria, planeación, creatividad y resolución de problemas”. Ahora bien, la Inteligencia Artificial es una rama de la Informática que busca crear inteligencia en base a lo matemáticamente computable. Aunque esta definición esta restringida al software y no a una base cibernética o biológica (como terapias genéticas o drogas nootrópicas[6] vistas en cintas como Gattaca y Limitless respectivamente), tiene la bondad de generalizar la inteligencia más allá de las mentes naturales.
Si bien el objetivo último de la Inteligencia Artificial siempre ha sido crear una inteligencia de capacidades iguales o superiores a la de un ser humano, el problema ha demostrado ser de una magnitud tan compleja que ha tenido que dividirse en las siguientes sub-áreas de estudio: razonamiento, conocimiento, planeación, aprendizaje, comunicación (procesamiento de lenguaje natural) y la habilidad de mover y manipular objetos [7]. Hasta el momento los logros han sido pequeños y, en su gran mayoría, parciales.
2 El debate dentro y fuera de la Inteligencia Artificial
Justamente así son estos predicadores y estudiosos que sostienen diversos puntos de vista de manera ciega y parcial... En su ignorancia son pendencieros y discutidores por naturaleza, cada uno sosteniendo que la realidad es así y así. Fragmento de la parábola de los ciegos y el elefante Udana 68-69 |
 |
|---|
Existen opiniones divergentes dentro y fuera de la Inteligencia Artificial sobre sus objetivos, su enfoque y los métodos logrados hasta el momento. Antes de llegar a cualquier conclusión es necesario delinear un contexto de por qué nadie se pone de acuerdo sobre la línea que se debe seguir.
Para empezar, la ciencia como búsqueda de la verdad resulta ser una tarea titánica en dos sentidos: por la inmensurabilidad de la verdad y por partir de lo desconocido. Por lo que el estudio científico práctico de cualquier cosa es un producto humano y social. Esta afirmación reconoce que, a pesar de que se puede construir un cuerpo bien fundamentado y sólido de conocimientos, es factible estar humanamente equivocado y empezar de nuevo. En consecuencia de esto y del tamaño del saber, se forman comunidades de expertos que validan las ideas y teorías con el fin de mantener y acrecentar el conocimiento. En otras palabras, se crean disciplinas científicas que trabajan en pequeños campos de estudio1.
Ahora bien, estas comunidades tampoco son infalibles y presentan problemas por su misma naturaleza. Por ejemplo, existen teorías que probaron ser correctas a la postre y que fueron refutadas durante mucho tiempo por miembros prominentes. Tal es el caso de la probabilidad Bayesiana, que durante siglos fue aislada de publicaciones científicas por los defensores de la probabilidad frecuentista hasta hace unas cuántas décadas. Esta interpretación de la probabilidad ayudó a Alan Turing a descifrar la máquina Enigma y, en la actualidad, es usada en técnicas de Aprendizaje Máquina [9].
Además, como cualquier tipo de organización, puede haber opiniones de todo tipo que lleven a descalificaciones y, a veces, a una inevitable división. Estas divisiones pueden llegar a formar otras disciplinas con otros campos de estudio. Aunque esto pudiera pensarse como un problema, en realidad es sano y constructivo que haya una diversidad de ideas diferentes para la ciencia. Ya que la exploración parcial de alguien o de algunos puede no conducir a toda la verdad, pero las exploraciones parciales entre muchos tal vez sí. En este mismo sentido, el estudio científico del cerebro, la mente y la inteligencia empezó hace poco menos de dos siglos, así que la diversidad de opiniones es natural en algo tan joven como la inteligencia artificial.
2.1 El estudio del cerebro, la mente y la inteligencia
La inteligencia artificial no es la única disciplina que busca describir e implementar mecanismos inteligentes de una u otra forma. De hecho, ni siquiera fue la primera, ya que se separó de la Cibernética2, la cual explora los sistemas regulatorios, sus estructuras, limitaciones y posibilidades [10] [11]. Por otra parte, hay quienes quieren separar las raíces de ramas de la IA, tal es el caso del Aprendizaje Máquina que últimamente ha sido conocido como Ciencia de Datos3.
Las neurociencias estudian el sistema nervioso y se puede decir que, entre otras cosas, estudian la inteligencia a nivel cerebral [12]. Por ejemplo, en [13] se logró hacer que un mono macaco dirigiera un brazo robótico con un implante cerebral. En cuanto al estudio de la mente, las ciencias cognitivas se encargan de estudiar sus procesos [14]. A modo de ejemplo, en [15] se presenta un experimento de cómo el lenguaje humano pudo haber evolucionado4.
Aunque se han formado barreras sintéticas para clasificar el estudio de todo lo relacionado por la inteligencia, también es cierto que los límites no son claros y que entre ellas hay intercambios de ideas. Es decir, algunos trabajos utilizan técnicas de otras disciplinas o algunos métodos se inspiran en hallazgos de otras. Específicamente, la interpretación de las señales recibidas por los implantes cerebrales se realiza mediante técnicas de aprendizaje de máquina [16]. Y, a su vez, nuevas técnicas de aprendizaje de máquina se inspiran en el funcionamiento neuronal [17].
Es incierto el futuro de cada una de las disciplinas y averiguar cuál de todas logrará finalmente la meta de la Inteligencia Artificial. Conviene destacar la opinión de Marvin Minsky, uno de los fundadores de la Inteligencia Artificial, en una entrevista que concedió en 2013 señala que la IA como disciplina tal vez desaparezca por falta de fuentes de empleo[18].
2.2 El truco del conejo en el sombrero o las críticas a la IA
Pequeños pasos, Ellie, pequeños pasos.
Ted Arroway a su hija
Cita de la película Contact
Existe un gran asombro en las personas cuando ven trucos de magia realmente excepcionales, pero usualmente este asombro se desvanece cuando se les explican los métodos y mecanismos para crear la ilusión. Sucede una reacción similar cuando se llega a algún avance en la IA. Por un lado, se busca el talón de Aquiles en el mecanismo inteligente, el cual está regularmente en las condiciones necesarias para que funcione. Por otro lado, el desencanto ocasiona que se le haga de menos al avance, se fije una nueva meta y se continúe investigando.
Un ejemplo ilustrativo de esto es Deep Blue: una computadora diseñada tanto en hardware como software hace casi dos décadas con el objetivo de vencer a Gary Kasparov, el entonces mejor ajedrecista del mundo [19]. En palabras claras, este sistema generaba miles de jugadas posibles a partir de un movimiento y escogía la mejor de acuerdo a las posiciones finales del tablero[20]. Así que, en realidad, la computadora no razonaba los movimientos que iba ejecutar y se basaba solamente en la Teoría de Juego y en el poder bruto de su hardware.
Esta opinión es compartida por Douglas Hofstadter, el escritor ganador del premio Pullitzer por Gödel, Escher, Bach, un libro con gran influencia entre los investigadores de IA. En una entrevista para The Atlantic [21] sostiene que “Para mí, como un pichón que vuela de ser una persona de IA, era evidente que no quería involucrarme en esas tretas. Era obvio: yo no quiero involucrarme en engaños al decir que el comportamiento de un programa estrafalario es inteligente cuando yo sé que no tiene nada que ver con la inteligencia. Y yo no sé por qué no hay más gente de esta manera”. Actualmente, él sigue investigando temas de las ciencias cognitivas y vive autoexiliado de conferencias académicas de IA.
Al mismo tiempo que es cierta esta crítica, también se puede ver a la inteligencia desde una óptica menos antropomórfica. En uno de los libros de texto sobre IA más famosos [23], Stuart Russell y Peter Norvig escriben que tal vez descubrir los mecanismos de la inteligencia es similar a lo que fue encontrar la aerodinámica. Al principio, muchos prototipos de cosas que volaran tenían alas semejantes a la de los pájaros, pero simplemente no podían emprender el vuelo. En la actualidad, las alas rígidas de metal de los aviones son una metáfora de la de los pájaros y, ciertamente, los aviones son más veloces que cualquier criatura voladora conocida.
En otra entrevista de The Atlantic [24], una opinión similar a la de Hofstadter respecto al aprendizaje estadístico es sostenida por el lingüista Noam Chomsky, figura de la Computación por agrupar las gramáticas formales. Adicionalmente, en un simposio organizador por el Massachusetts Institute of Technology en 2011, Chomsky consideró que los modelos estadísticos actuales del lenguaje son un éxito ingenieril, pero irrelevantes a la ciencia; y que lo que importa es encontrar principios lingüísticos y no modelarlos como hechos exactos. Su crítica le valió una respuesta de Peter Norvig[23]. Entre otras cosas, le responde que “la ciencia es una combinación de recolectar hechos y hacer teorías; ninguna puede progresar por su cuenta. Pienso que Chomsky se equivoca al empujar la aguja hacia la teoría que sobre los hechos; en la historia de la ciencia, la laboriosa acumulación de hechos es el modo dominante, no una novedad. La ciencia de entender el lenguaje no es diferente a otras en este respecto”.
Al igual que Hofstadter y Chomsky, Marvin Minsky también ha señalado que la IA ha perdido su camino inicial y que se ha dedicado a resolver pequeñas tareas de ciertos dominios [25]. Seymour Papert, otro fundador de la IA, comparte la misma opinión que su amigo Minsky. Ambos ven con malos ojos el resurgimiento de las redes neuronales como el enfoque dominante actual, ver Fig. 1. En el libro de 1969 [26], lograron relegar a las redes neuronales a un segundo plano utilizando argumentos y demostraciones matemáticas de lo que se sabía en ese tiempo. Metafóricamente hablando, demostraron que no se podía entrar a una casa por la puerta principal, aunque tiempo después alguien encontró la entrada por la puerta trasera.
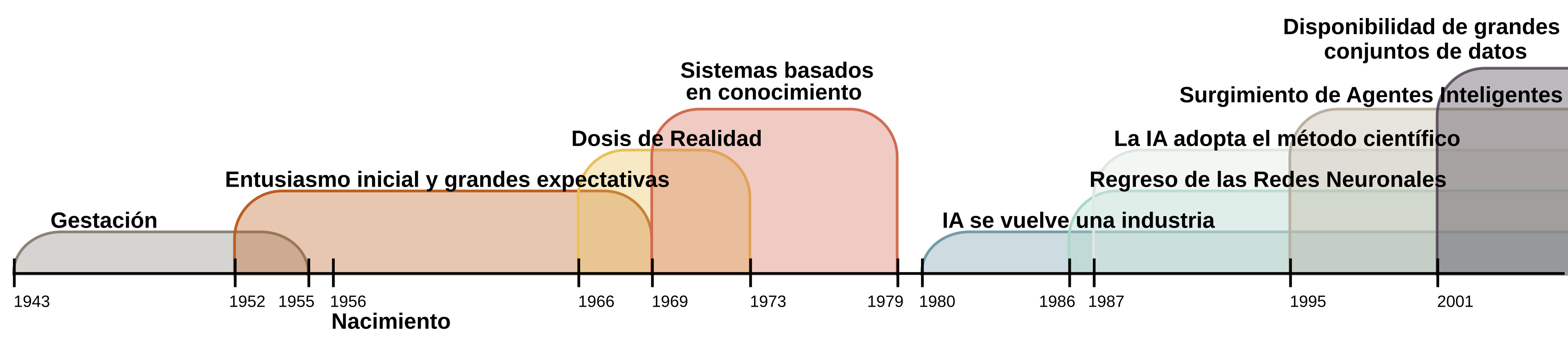 |
|---|
| Figura 1: Línea de tiempo de la historia de la Inteligencia Artificial. Basado en [22]. |
Respecto a esta cuestión, es preciso indicar que la ciencia es una tarea competitiva en la que cada proyecto busca financiamiento de muchas fuentes. En consecuencia, cada investigación tiene una prioridad y asignación de recursos diferente. Aunque manteniendo su postura, el mismo Papert explica en [27]5 que su intención no era matar a un campo de estudio, sino que simplemente querían asegurar el escaso patrocinio de la agencia militar Defense Advanced Research Projects Agency (DARPA).
En la actualidad, además de recursos otorgados por el gobierno también los hay otorgados por compañías. Y, si bien se trabaja en pequeños objetivos, la sociedad a nivel global ha percibido los pequeños avances al haber sido beneficiada por ellos. Por otra parte, esto ha asegurado que la investigación no sólo continúe en laboratorios de Universidades, sino también en el sector industrial. Así que, a diferencia de las misiones espaciales, el desarrollo de la IA ha seguido gracias a la aparición de una industria. Por último, es preciso señalar que el objetivo de Deep Blue no era sólo lúdico y académico, ya que su arquitectura fue usada en modelos financieros, en descubrir patrones en grandes bases de datos y en aplicaciones de la dinámica molecular para desarrollar nuevas medicinas[19].
3 La tendencia actual de la IA
Durante las tres últimas décadas, la Inteligencia Artificial ha sido marcada por el surgimiento del aprendizaje de máquina estadístico como paradigma principal en la investigación. En particular, se ha caracterizado por el regreso de las redes neuronales artificiales, uno de sus campos que ha existido desde los inicios de la IA. Desde hace casi diez años, nuevas técnicas producidas por este enfoque, bajo el nombre de aprendizaje profundo, han tenido un progreso significativo en los resultados de áreas como el procesamiento lenguaje natural y la visión por computadora.
Aunque en este breve ensayo no se comentan ideas de la vieja escuela de la IA, mejor conocidas como Good Old Fashion Artificial Intelligence (GOFAI), es importante mencionar que las ideas y modelos no son dinosaurios que terminan exhibidos como fósiles de museo. Por ejemplo, los sistemas expertos de los años ochenta son utilizados en la tecnología empresarial de hoy y son conocidos como reglas de negocios. Además, hay modelos que años atrás no pudieron llevarse a cabo por la poca capacidad instrumental en ese momento, pero que ahora son retomados con gran éxito.
3.1 El aprendizaje de máquina
Tom Mitchell define que un programa aprende una tarea cuando su desempeño medido respecto a una métrica mejora con la experiencia[28]. Por ejemplo, la verificación de caras en fotografías es una tarea cuyo desempeño ha alcanzado el nivel humano, de acuerdo a los resultados presentados por un grupo de investigadores de Facebook en [29]. Esta tarea es del tipo supervisada porque se utiliza un conjunto de entrenamiento con fotos en las que se conoce la ubicación del rostro a verificar u objetivo. La experiencia se adquiere conforme se le va presentando al programa cada foto de entrenamiento una o más veces. Una métrica estándar para medir el desempeño es contar el número de fotos en las que se identificó correcta (Verdadero positivo) e incorrectamente (Falso positivo) el rostro de la persona.
Para comparar objetivamente el aprendizaje del programa respecto a diferentes períodos de entrenamiento u otros programas, se emplea otro conjunto de fotografías diferente que al usado durante entrenamiento. A este conjunto se le conoce simplemente como el conjunto de pruebas. Se dice que el programa con mejor desempeño en el conjunto de prueba ha generalizado mejor el entrenamiento.
Ahora bien, el aprendizaje supervisado consiste en encontrar la mejor manera de distinguir los objetivos a partir de su representación. Hay diversas recetas o algoritmos que hacen esto con cualquier tipo de representación, pero se ha demostrado que no hay ninguno que sea superior en todas la tareas6. Por lo que usualmente se compara su nivel de generalización con los conjuntos de prueba. En cuanto a la representación del objetivo, esta depende del dominio del problema. Por ejemplo, para distinguir diferentes clases de vinos se pueden usar atributos como el nivel de alcohol, su textura, la cantidad de magnesio, etcétera [30].
Además del algoritmo de aprendizaje seleccionado, una mejor generalización depende en gran medida de cómo esté representado el problema. En el caso de las imágenes, su representación básica son arreglos bidimensionales de números, mejor conocidos como matrices, que representan la intensidad uno o más canales de color, es decir, de fotos en escala de grises o a colores respectivamente. Esta representación en bruto poco ayuda para la identificación de caras, porque las áreas de los rostros son de diferentes tamaños entre fotos, no miran siempre al mismo lado y los colores cambian respecto a la iluminación. En consecuencia, el enfoque propuesto por Facebook consiste en rotar virtualmente las caras de las personas para tener una vista frontal y a partir de esta se crea una representación más robusta de la cara, ver fig. 2.
 |
|---|
| Figura 2: Rotación virtual de un rostro y creación de una representación más robusta. Imagen original de Facebook. |
Es preciso mencionar que hay otros dos tipos de aprendizaje de máquina: el no supervisado y por refuerzo. En el aprendizaje no supervisado se desconocen las clases de antemano y se buscan a partir de los datos de entrada. Por ejemplo, Google News diariamente agrupa miles de noticias en categorías coherentes, que el usuario identifica como historias periodísticas [31]. Por otra parte, en el aprendizaje por refuerzo un agente aprende con base en recompensas y castigos en un entorno con el que interactúa. Un entorno clásico de simulación para crear nuevas técnicas son videojuegos, ya que el agente tiene metas claras y castigos como conseguir power-ups y no perder vidas. Un nuevo enfoque profundo presentado en Nature [32] aprendió a jugar distintos juegos de Atari7.
3.2 Las redes neuronales artificiales
Desde inicios de los años cuarenta se empezaron a crear modelos del funcionamiento individual de células neuronales o neuronas. En 1946, Donald Hebb postuló una ley que describe la interacción neuronal o sinapsis y que da lugar al aprendizaje. En términos simples, la ley establece que cuando dos neuronas se activan repetidamente al mismo tiempo, estas tienden a asociarse y, como consecuencia, a facilitar su actividad [33]. Para finales de los cincuenta, esta idea llevó a Frank Rosenblatt a proponer un modelo matemático de una neurona llamado perceptron. Si bien los fisiólogos abandonaron este modelo porque su simplicidad no refleja la complejidad biológica8, su desarrollo continuó en la comunidad de la Inteligencia Artificial9.
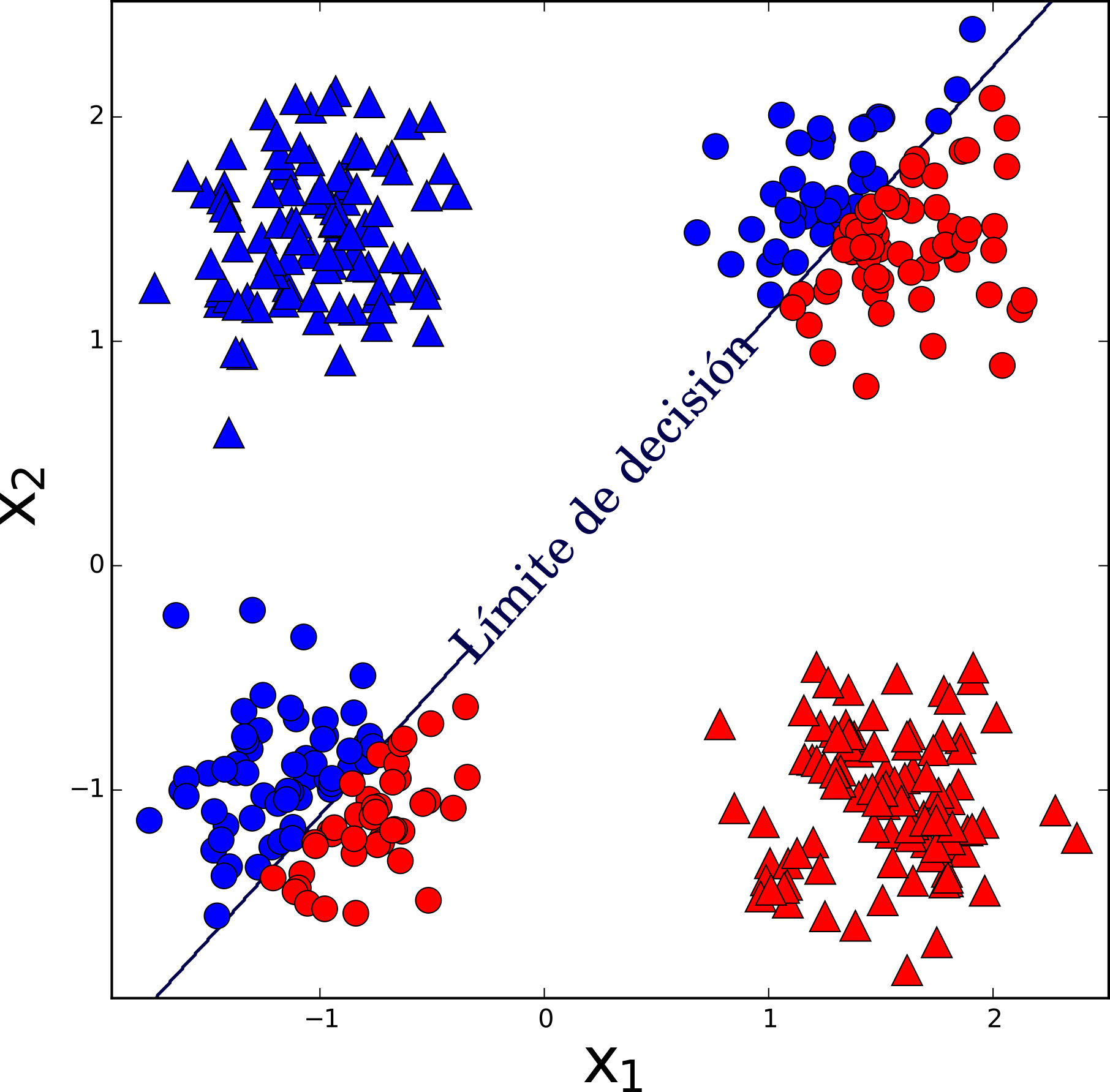
El objetivo del perceptron es crear un límite lineal entre dos clases de cosas con base en sus atributos expresadas numéricamente a partir de los ejemplos proporcionados en su aprendizaje. Por ejemplo, en la fig. 3 se muestra el entrenamiento de un perceptron que distingue entre animales felinos y caninos usando como atributos el tamaño y el nivel de domesticación. En esta misma figura se puede apreciar como se actualiza el límite lineal conforme se le presentan más ejemplos al perceptron.
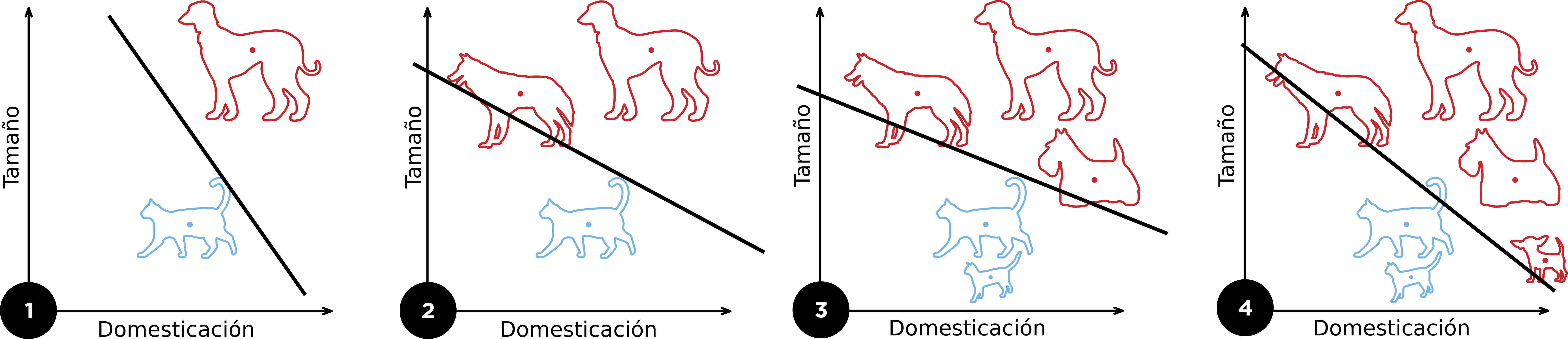 |
|---|
| Figura 3: Ejemplo de la actualización del límite entre las clases de animales felino y canino durante el entrenamiento de un perceptron. Adaptado de Elizabeth Goodspeed de Wikipedia Commons. |
En términos matemáticos, el límite lineal \(v\) que ayuda a separar las clases está definido como \(v=\sum_{i}^{n}w_i\cdot x_i=w_0\cdot x_0+w_1\cdot x_1+\ldots+w_n\cdot x_n\) en el que \(x_{0}, x_{1}, \ldots, x_{n}\) representan los atributos de las clases y \(w_{0}, w_{1}, \ldots, w_{n}\) son los pesos sinápticos. En el caso del perceptron que distingue entre animales caninos y felinos la ecuación describe a un plano y se define como
\[v=w_0 \cdot 1+w_1 \cdot \text{domesticación}+w_2 \cdot \text{tamaño}\]La línea que se ilustra en la fig. [fig:ejemploPerceptron] es cuando \(v=0\), precisamente en el valor límite de decisión. Es decir, la línea que está definida como:
\[\text{tamaño}=\frac{w_1}{w_2}\cdot \text{domesticación}+\frac{w_0}{w_2}\]Adicionalmente, se debe aplicar una función de activación binaria al valor de \(v\). Una función simple \(phi\) para este ejemplo podría ser expresada bajo las siguientes dos reglas:
-
Si el valor de \(v\) es mayor que \(0\), entonces \(y=1\) y se trata de un canino.
-
Si el valor de \(v\) es menor o igual que \(0\), entonces \(y=0\) y se trata de un felino.
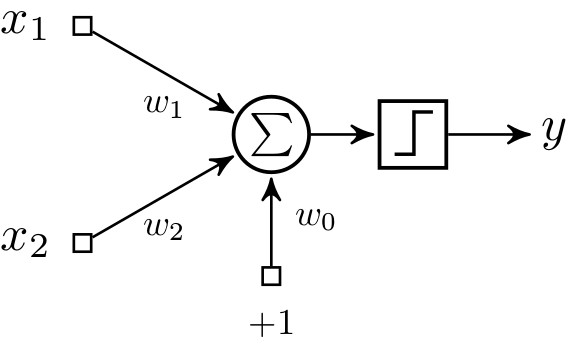
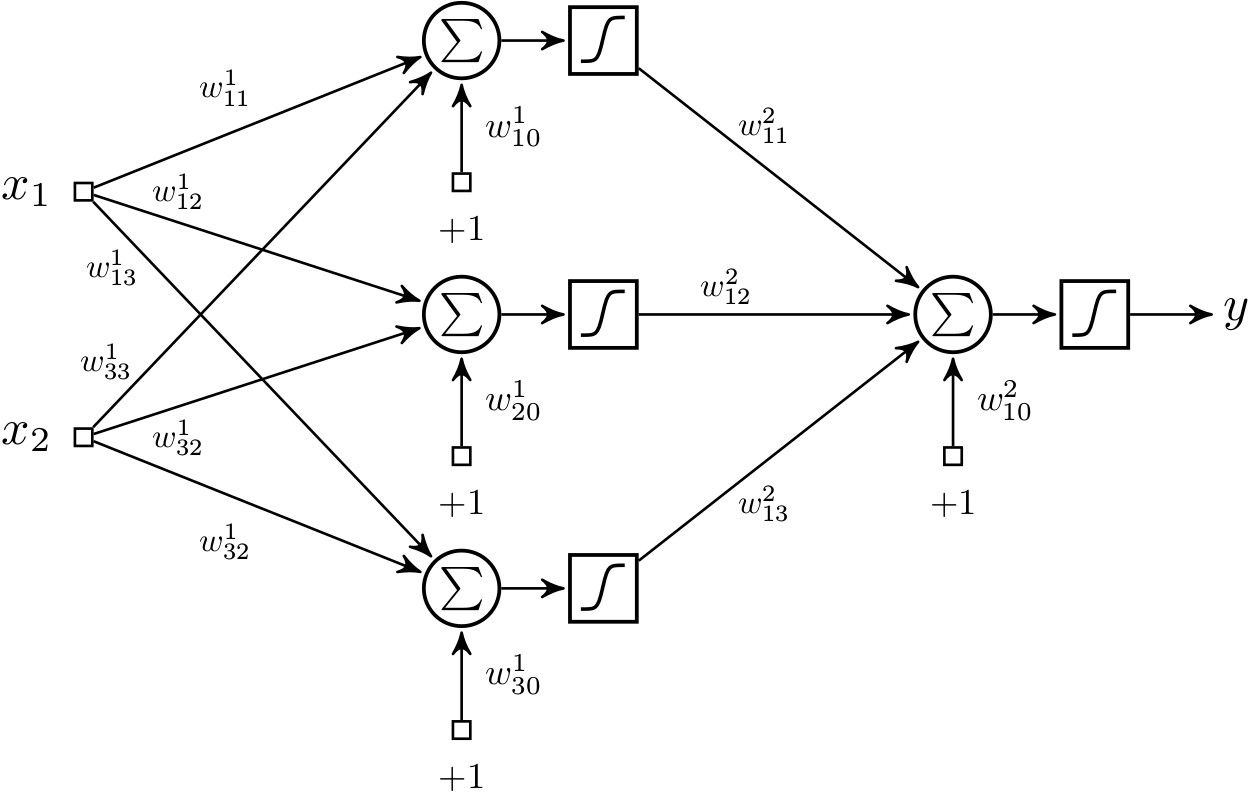
Finalmente, el perceptron puede ser expresado con la siguiente ecuación que se ilustra en la fig. 4a:
\[y=\phi(v)=\phi(v)=\phi(\sum_{i}^{n}w_i\cdot x_i)=\phi(w_0\cdot x_0+w_1\cdot x_1+\ldots+w_n\cdot x_n)\]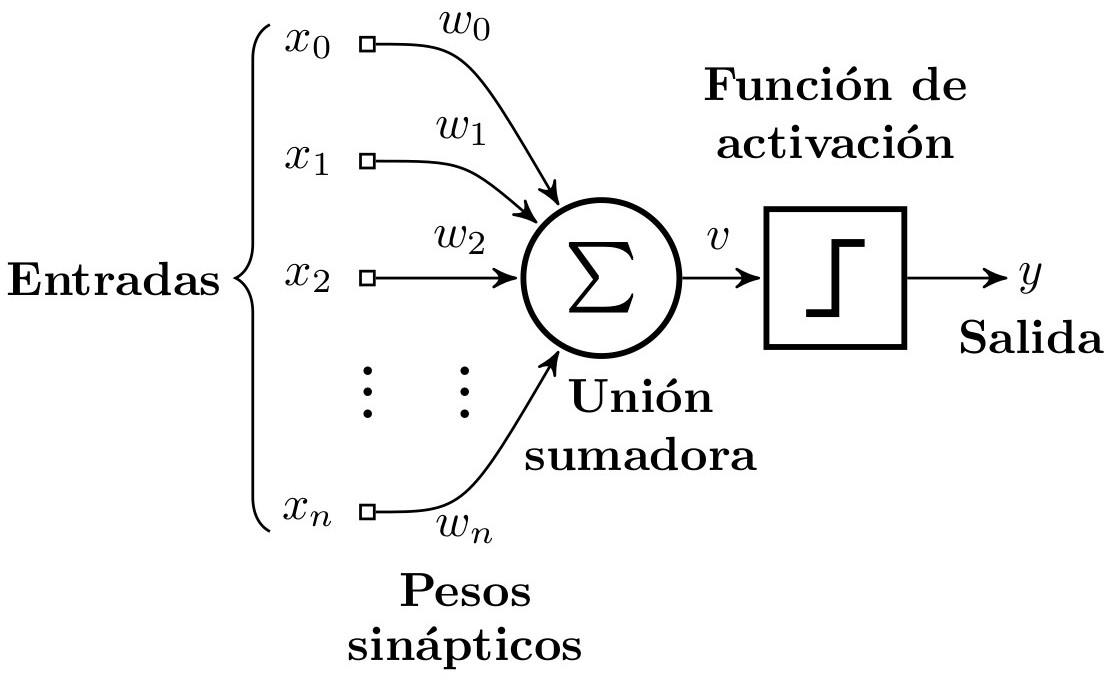 |
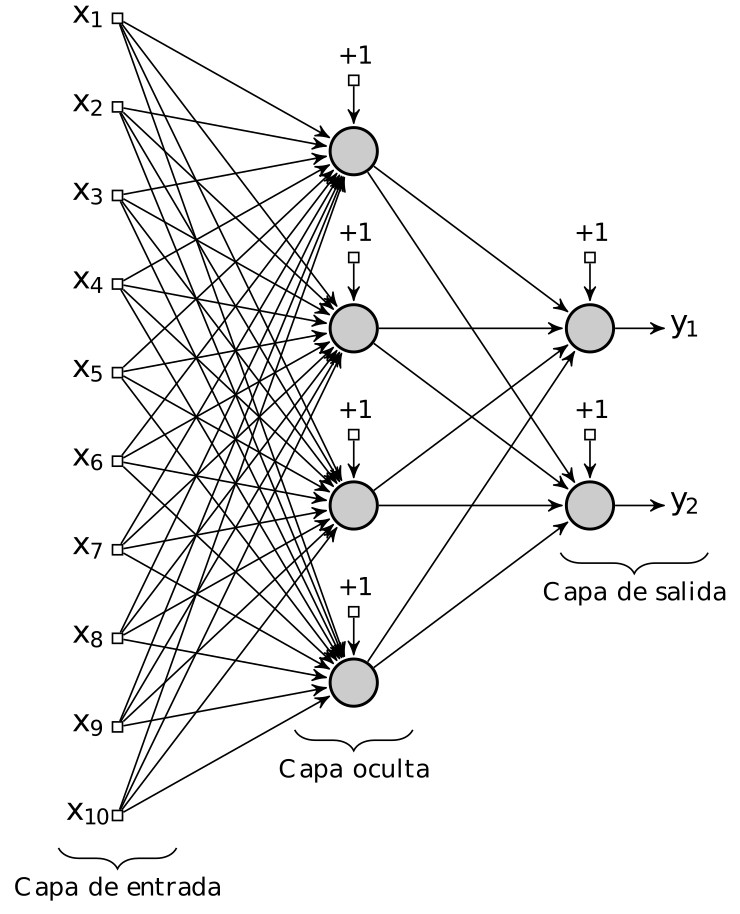 |
| (a) | (b) |
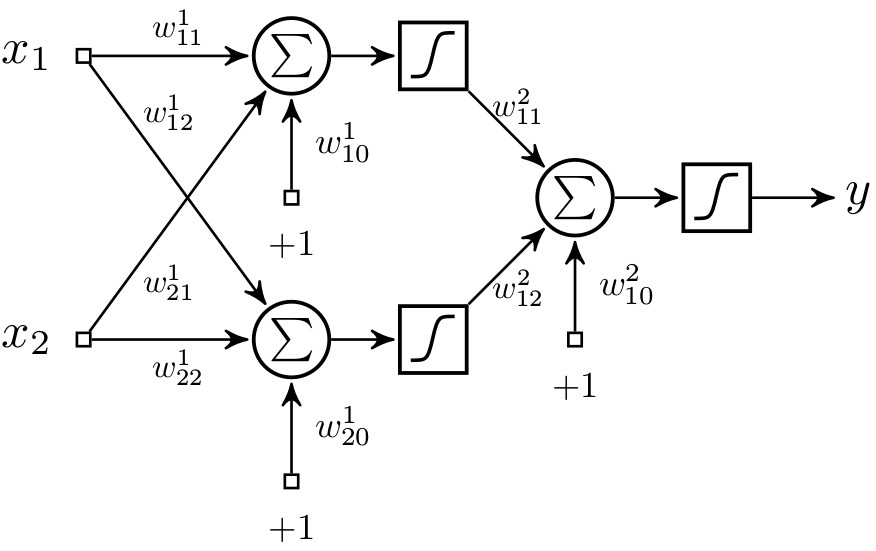
| Figura 4: Diagrama de un perceptron y una red multicapa de perceptrones. (a) Un perceptron con n entradas. (b) Una red multicapa de perceptrones con 10 entradas, 4 unidades en la capa oculta y 2 unidades en la capa de salida. Nota: cada nodo gris contiene una unidad sumadora y una función de activación sigmoidal. |
|---|
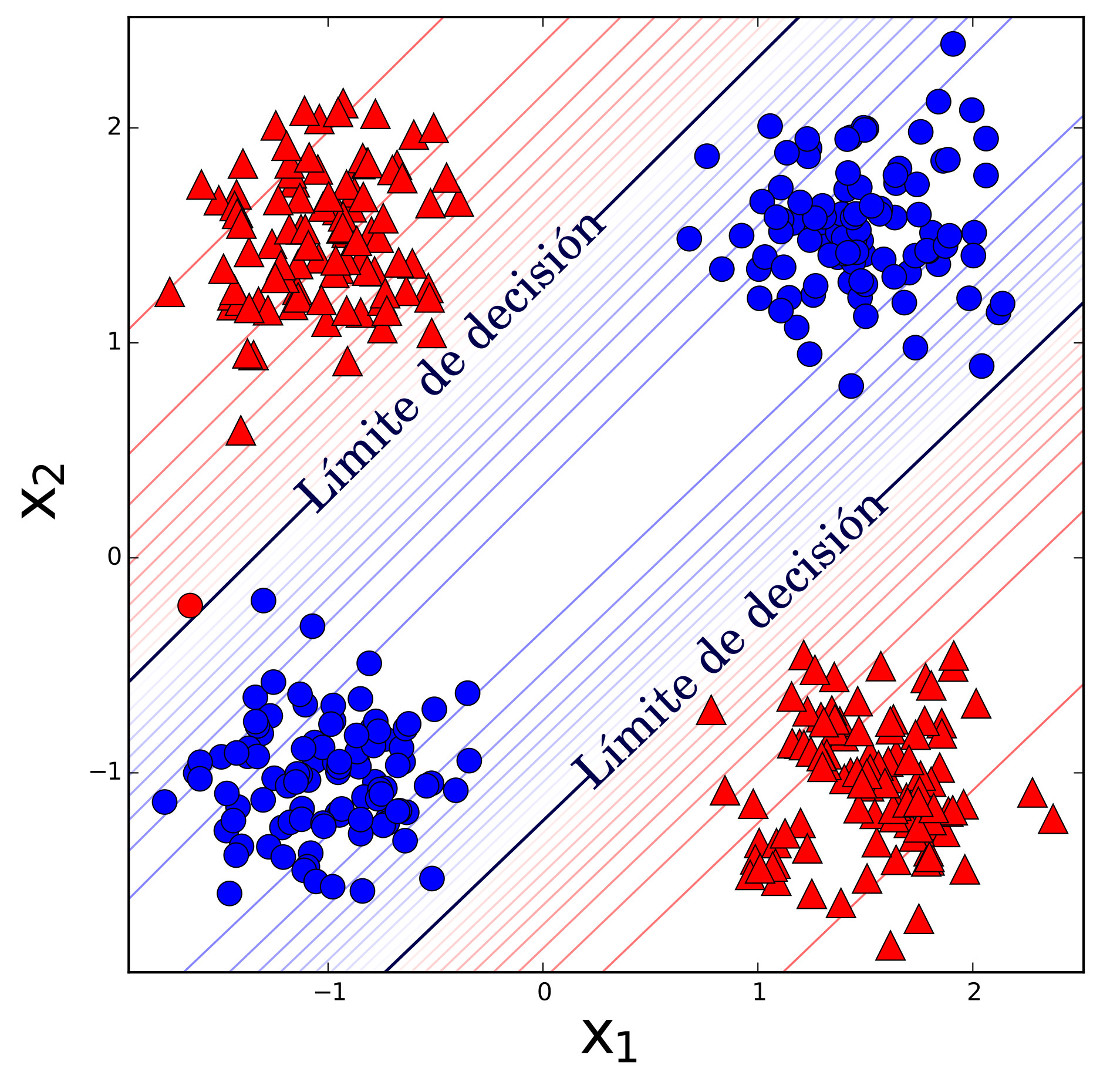
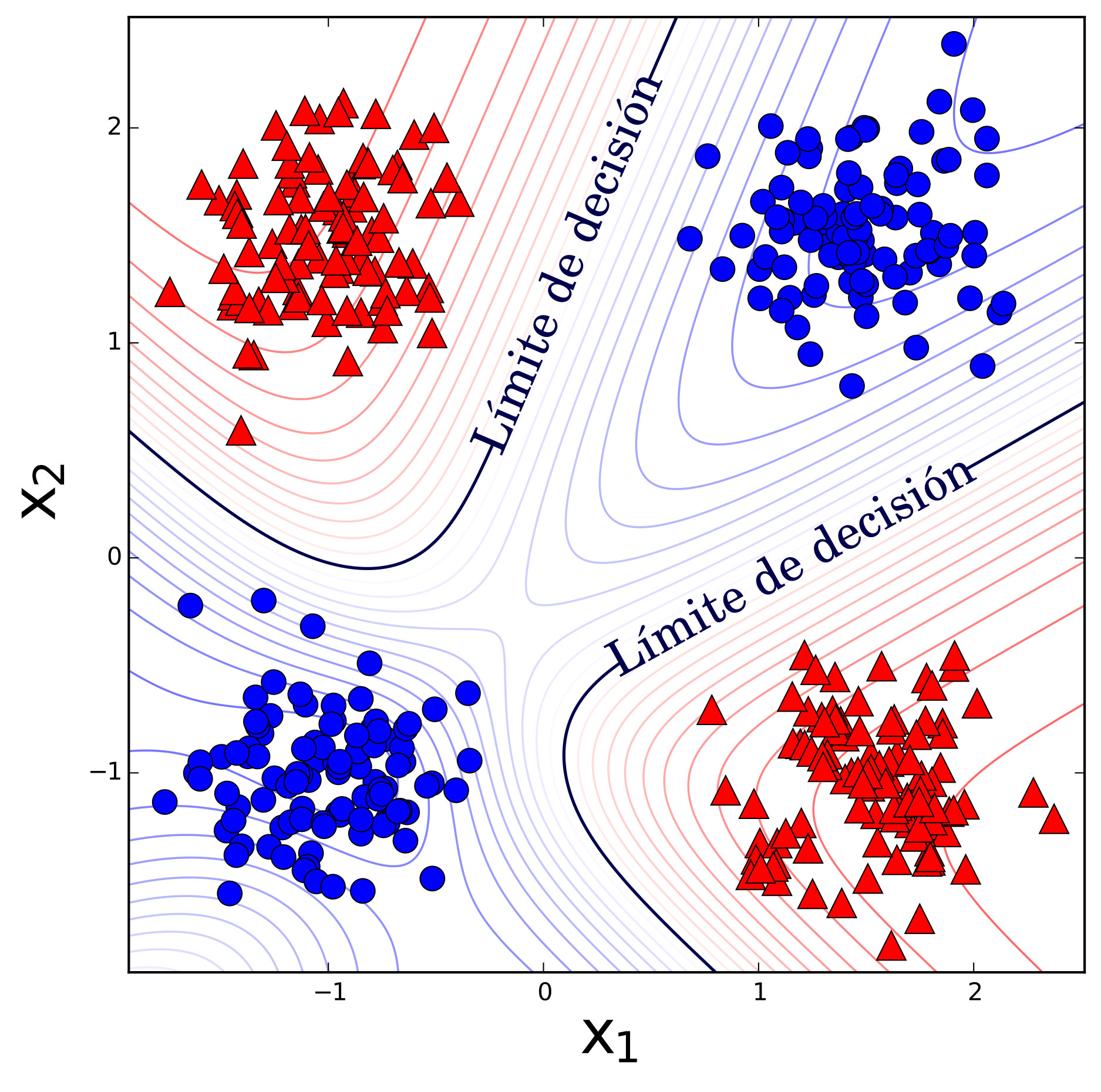
Ahora bien, el algoritmo del perceptron busca matemáticamente los valores de los pesos \(w_{0}, w_{1}, \ldots,\) \(w_{n}\) que separan a dos clases de manera lineal. La debilidad del perceptron es justamente que sólo encuentra límites lineales entre clases, pero los límites entre clases de problemas comunes no son lineales. Por ejemplo, en la Fig. 5a se presenta el resultado de un perceptron en un problema de clasificación no-lineal entre círculos y triángulos10. Se puede apreciar que el mejor resultado del perceptron es colocar al límite de decisión justo a la mitad y tener un error del \(50\%\).
Para solucionar este inconveniente se necesita combinar dos o más perceptrones y formar una red multicapa de perceptrones (RMP) que produzca límites de decisión no lineales. Si bien tanto el problema como su solución fueron reportados en 1969 por Minsky y Papert en [26], lo que condenaría a las redes neuronales fue la conclusión de que no había ningún algoritmo de entrenamiento de RMP a la vista[34].
A principios de la década de los setenta, muchos investigadores encontraron distintas versiones de cómo entrenar las redes multicapa de perceptrones [35], pero no tuvieron ningún eco. Entre ellos destaca el entonces joven estudiante de doctorado Paul J. Werbos, al quien se le acredita ahora de haber descubierto la manera de entrenarlos en su tesis doctoral de 1974. Werbos narra en [36] las penas que sufrió para que su descubrimiento pudiera ser publicado y de cómo al final éste fue relegado y olvidado por la academia. En sus propias palabras, dice que de esta experiencia aprendió mucha acerca de la herejía, los tabúes y del sistema académico[34].
Nuevamente, a mediados de los ochenta, otra generación de investigadores redescubren por separado el método para entrenar a las redes multicapa de perceptrones. Sin embargo, el trabajo que es considerado como la piedra angular es [37], presentado por David Rumelhart, Geoffrey Hinton y Ronald Williams. En este ensayo se presenta el algoritmo de retropropagación que consiste en propagar las señales de entrada hasta las salidas, compararlas con los valores reales y propagar los errores hacia atrás. Adicionalmente, la función de activación deja de ser binaria y se vuelve continua con forma de S (función sigmoidal).
 |
 |
(a) Perceptron
 |
 |
(b) Red multicapa de perceptrones de 2x2x1
 |
 |
(c) Red multicapa de perceptrones de 2x3x1n
| Figura 5: Comparación del desempeño entre un percetron y dos redes multicapa de perceptrones para un problema de clasificación no-lineal. |
|---|
Retomando el problema de clasificación no-lineal de la fig. 5, se puede apreciar cómo las RMP tienen un mejor desempeño que el perceptron por sí solo. Si bien la adición de dos unidades más sigue teniendo un error del \(0.5\%\), como se muestra en la fig. 5b; la adición de tres unidades más no tiene error alguno, como se muestra en la fig. 5c. Por otra parte, la fig. 5 muestra las curvas de nivel para diferentes grados de clasificación gracias a las funciones de activación sigmoidales, a diferencia de la activación binaria del perceptron.
Hasta hace poco, las arquitecturas comunes de RMP consistían de tres capas como la que se muestra en la fig. 4b, pero estas pueden tener varias capas ocultas. Aunque teóricamente el tener un sola capa oculta con una gran cantidad de perceptrones puede aproximar cualquier función11, ésta tal vez sea demasiado grande ocasionando que sea imposible de entrenar y que generalice correctamente. Las arquitecturas con varias capas ocultas o profundas tratan de resolver estos problemas [38].
Las arquitecturas profundas comenzaron a ser investigadas desde 1993 por la misma generación de los ochenta, pero tuvieron un éxito definitivo hasta el 2006. Entre los miembros de esta generación destacan Geoffrey Hinton, Yoshua Bengio y Yann Lecun (otro re-descubridor del algoritmo de retroprogación). Además de encontrar algoritmos eficientes de aprendizaje para las redes profundas, otro factor determinante para su éxito fue el aumento del poder de procesamiento ofrecido por clústers de tarjetas gráficas12.
 |
|---|
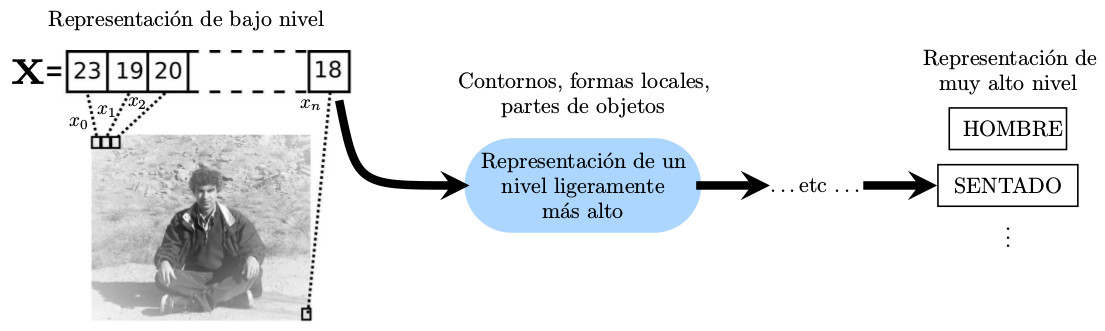
| Figura 6: Ejemplo de representaciones jerárquicas del aprendizaje profundo desde un bajo hasta un alto nivel. Adaptado de [39] |
El objetivo del aprendizaje profundo es aprender jerarquías de características, las cuales se basan en la jerarquía previa como se ilustra en la fig. 6. En este ejemplo, un vector con los colores de los píxeles que representan una imagen de entrada se va transformando gradualmente en diferentes niveles de representación. Naturalmente, se desconoce por adelantado la representación indicada para todos los niveles de abstracción[39].
La industria de los teléfonos inteligentes volteó la vista hacia al aprendizaje profundo en 2009, cuando se rompió un record de precisión en el procesamiento de lenguaje natural [40]. Dos años después, compañías como Apple utilizaban el aprendizaje profundo para asistentes digitales activados por voz como Siri. Asimismo, Google lo implementó en sus sistema de reconocimiento de voz, logrando una reducción de \(25\%\) de errores en palabras.
Uno de los logros del aprendizaje profundo fue el haber ganado la competencia internacional ImageNet de 2012. En esta competencia se le entrega a los equipos un millón de imágenes cotidianas con objetos como bicicletas, personas, ruedas etiquetados por personas para el entrenamiento de sistemas. La competencia la gana el equipo cuyo porcentaje de error sea el menor en un conjunto de validación desconocido. Antes de que el equipo de Geoffrey Hinton entrara a la competencia, el porcentaje de error era de alrededor del \(25\%\), su equipo lo redujo al \(15\%\). Hinton y su equipo fueron contratados por Google y su sistema fue empleado en el software de búsqueda de fotos de Google+. El sistema de Hinton procesaba 60 millones de parámetros y consistía de 650 mil perceptrones con un total de 630 millones de conexiones. El sistema tuvo un tiempo de entrenamiento de una semana [41].
En los últimos años, las grandes compañías tecnológicas mundiales se han interesado en la investigación de IA de punta. Por ejemplo, compañías como Google, Facebook y Baidu han contratado expertos en el área de la talla de Hinton, Norvig, Lecun y Andrew Ng. Más aún, Mark Zuckerberg sorprendió a la comunidad mundial de aprendizaje máquina al visitar la conferencia más importante del área en 2013 [42]. Esto significa una transformación de empresas tecnológicas hacia sistemas basados en algoritmos inteligentes.
4 Una humilde promesa
Existen muchos perspectivas de lo que el desarrollo de la ciencia le traerá a la humanidad, en especial la IA. Esta sección únicamente habla de la promesa de la IA de liberarnos del trabajo. Esta promesa es humilde comparada con muchas otras como la verdadera creación de una inteligencia artificial o la trascendencia, que es pasar una mente orgánica a una base inorgánica. Por ahora, todo indica que ninguna de las dos están a la vuelta de la esquina.
De mantenerse un paso constante en la búsqueda de métodos inteligentes y sus aplicaciones, es factible que en diversos grados la humanidad se libere del trabajo. Es conocido que la IA ya ha empezado a usarse en la producción y verificación de bienes, como la clasificación de frutos recolectados o, más recientemente, la construcción de edificios [43]. Pero justo ahora está automatizando tareas consideradas de más alto nivel en profesiones como la medicina, la abogacía o el desarrollo de software[44].
La razón de esto es que existen tareas de alto nivel que en realidad son rutinarias. Por ejemplo, en una consulta médica, un médico transforma los padecimientos y mediciones corporales de un paciente en un diagnóstico y una prescripción. Los beneficios de esta automatización saltan a la vista: costos más bajos y una calidad estándar del servicio. Actualmente, IBM pretende utilizar Watson como asistente para el diagnóstico médico[45]. No sería descabellado pensar que en un futuro cercano hubiera consultas médicas automatizadas en línea, partiendo del hecho que un tercio de los estadounidenses utilizan Google como herramienta de diagnóstico[46]. Más aún, por qué no imaginar laboratorios de estudio y diagnóstico médicos totalmente automatizados que beneficien a comunidades remotas o marginadas.
La humanidad no debería tomar una postura ludita ante el progreso la IA, porque en realidad es una oportunidad de disfrutar más la vida. La liberación del trabajo puede conducir a dedicar el tiempo a cultivarnos, a hacer cosas que queremos y a disfrutarnos entre nosotros13. Incluso si la transición no es completa, es la oportunidad perfecta para dejar de hacer cosas repetitivas y realizar tareas más creativas y complejas.
5 Peligros y riesgos
...Yo no trabajo en no volver maligna a una IA por la misma razón que no me preocupa el problema de sobrepoblación en Marte. Andrew Ng |
 |
|---|
A finales del año pasado, la BBC reportaba sobre el temor de Stephen Hawking y Elon Musk acerca de la amenaza que representa la IA a la humanidad [48]. Las declaraciones de Hawking fueron que “El desarrollo de una Inteligencia Artificial completa puede conjurar el final de la raza humana. Ésta podría despegar por sí misma y rediseñarse a un ritmo creciente. Los humanos, quienes están limitados por su lenta evolución biológica, no podrían competir y serían reemplazados”.
Las declaraciones de Hawking no pasaron desapercibidas por la comunidad de IA y tuvieron respuesta a inicios del año [49] [50]. En concreto, las afirmaciones de Hawking son correctas, pero el progreso en la materia está lejos de ser una amenaza real para la humanidad en su conjunto. En una conferencia en California [49], Andrew Ng respondió que “hay mucha alharaca de que la IA creará robots malignos súper-inteligentes. Esto es una distracción innecesaria. Aquellos de nosotros en el frente de la programación estamos emocionados por la IA, pero no vemos un camino realista para que nuestro software se vuelva consciente. Hay una gran diferencia entre inteligencia y conciencia. Podría haber una carrera de robots asesinos en el futuro lejano, pero yo no trabajo en no volver maligna a una IA por la misma razón que no me preocupa el problema de sobrepoblación en Marte”.
Ciertamente, si las declaraciones no hubieran sido pronunciadas por una celebridad, que además es ajena a la materia, entonces habrían sido desechadas inmediatamente por su falta de valor. Pero las declaraciones exponen peligros latentes originalmente presentados en un libro del filósofo de la ciencia Nick Bostrom y que son apoyadas por Stuart Russell [51]. El libro se llama Superinteligencia: caminos, peligros y estrategias y define a una superinteligencia como “cualquier intelecto que exceda por mucho el desempeño cognitivo de los humanos en virtualmente todos los dominios de interés”[52]. Los dominios a los que se refiere Bostrom no sólo son los clásicamente etiquetados como intelectuales, sino que lo extiende a otras habilidades como, por ejemplo, las sociales y de comunicación. Es decir, una superinteligencia podría manipular a cualquier persona mediante su simpatía y carisma. Bostrom establece que hay diversos caminos para llegar a la superinteligencia como los mencionados en la sección 1, pero el más probable es la IA. Bostrom también expone diversos escenarios hipotéticos de cómo los humanos no podríamos controlar una IA.
Uno de los verdaderos problemas de las declaraciones de Hawking es que existen otros riesgos en el corto y mediano plazo que no están recibiendo atención mediática. Por ejemplo, Thomas G. Dietterich se une a la discusión y presenta algunos riesgos técnicos actuales en [53]. Uno de los puntos que Dietterich expone que los sistemas inteligentes son muy difíciles de probar y verificar debido a su complejidad inherente. Asimismo, plantea que los sistemas inteligentes son vulnerables a ataques informáticos como cualquier otro software.
Por otro lado, la socióloga Sherry Turkle14 describe en su libro Alone Together [54] como la humanidad ha creado herramientas a lo largo del tiempo y estas la han transformada. Su preocupación es cómo las tecnologías actuales han ido aislando a las personas del verdadero contacto humano y la manera en que las antropoformizamos. Entre otros muchos ejemplos, se puede citar el de cómo se han ido construyendo robots para el cuidado y compañía de ancianos, porque las personas los han ido marginalizando.
En el mismo sentido, el investigador Mark Bishop advierte en [50] que está “particularmente preocupado por el potencial despliegue militar de los sistemas de armas robóticas -sistemas que pueden tomar la decisión de participar militarmente sin intervención humana-precisamente porque la actual IA no es muy buena y fácilmente puede forzar a que las situaciones escalen con consecuencias potencialmente aterradoras”. También explica que “es fácil estar de acuerdo que la IA puede suponer una verdadera “amenaza existencial” para la humanidad sin tener que imaginar que alguna vez alcanzará el nivel de inteligencia sobrehumana”. Tal vez esta respuesta y el hecho de que el Reino Unido se negó a prohibir el desarrollo de armas inteligentes propiciaron que Hawking firmará una carta abierta junto a una millar de expertos en el área en julio de este año [55].
Por último, Ng en otras conferencias advierte que el verdadero problema en el corto plazo será el desempleo ocasionado por el acelerado cambio que supone la introducción de la IA en muchas industrias [56]. Si bien en la sección 4 se presentaron algunos beneficios de la liberación del trabajo, esta liberación también podría traducirse como desempleo. Esto es una clara amenaza para países cuyos niveles educativos son bajos y que, por lo mismo, no pueden adaptarse al cambio.
6 Observaciones finales
Tradicionalmente, la inteligencia es un concepto difícil de definir y fácilmente antropoformizado. Hasta hace poco menos de un siglo comenzó su estudio de manera formal y la búsqueda de cómo automatizarla. Naturalmente, al ser un trabajo colectivo humano, esta tarea ha tomado diversos caminos. Pero el que existan opiniones divergentes promueve la competencia sana y la exploración de diferentes posibilidades. Asimismo, la tarea está abierta a gente de muchas carreras como las matemáticas, la física, la ingeniería, la psicología, etcétera.
La tendencia actual en la investigación son las redes neuronales artificiales, las cuales nacieron al mismo tiempo que la IA. Nuevos algoritmos de entrenamiento y equipo de procesamiento paralelo masivo han permitido grandes avances en la materia. Estos avances han provocado un gran interés por parte de grandes compañías tecnológicas. Pero cabe aclarar que estos avances están lejos de resolver el problema y personajes como Yan Lecun advierten que el entusiasmo desmedido pueden desembocar en falta de fondos y estancamiento.
Es claro que una superinteligencia computacional es una amenaza latente en un futuro lejano, pero destapar este tema es importante por dos razones. Primero, porque es preocupante que las personas no estén informadas al respecto y tome importancia por una celebridad ajena a la discusión. Segundo, porque los científicos muchas veces tienen una visión parcial de las cosas y la ciencia, al final de cuentas, le pertenece a la sociedad. Por otra parte, más allá de los peligros lejanos de la IA, existen riesgos en el corto y mediano plazo que merecen atención. Si bien la IA ofrece grandes sueños, estos se pueden transformar en pesadillas si las sociedades no están preparadas para cambios acelerados.
7 Recomendaciones
Además de la fuentes citadas en el texto, aquí unas fuentes que pueden inspirar un acercamiento a la IA:
-
Daniel Dennett es un celebre filósofo que se ha dedicado a temas de la mente, la conciencia y el libre albedrío. Entre sus libros famosos se encuentraConsciousness Explained.
-
Douglas Hofstadter es un autor clásico de Gödel, Escher, Bach: An Eternal Golden Braid y I Am a Strange Loop.
-
Roger Penrose es un físico inglés famoso y expone su negativa a alcanzar una inteligencia en The Emperor’s New Mind Concerning Computers, Minds and the Laws of Physics.
-
Marvin Minsky escribe sus teorías para el público en general en The Society of Mind y su continuación en The Emotion Machine: Commonsense Thinking, Artificial Intelligence, and the Future of the Human Mind.
-
Nick Bostrom explica en Superintelligence: Paths, Dangers, Strategies numerosos casos hipotéticos de cómo una superinteligencia podría tomar el control y hace echar volar la imaginación como algún cuento de Isaac Asimov. Explica a detalle por qué las tres leyes de la robótica son una ingenuidad.
-
Nils Nilsson hace un extenso recorrido por la historia de la IA en The Quest for Artificial Intelligence: A History of Ideas and Achievements. Si bien el libro se va tornando más técnico conforme pasan los capítulos, hay excelentes anécdotas al principio y puede descargarse libremente.
-
Documentales de la seria BBC Horizon: The Hunt for AI, Where’s My Robot?, Why Do We Talk?, The Age of Big Data, How Does Your Memory Work? y Battle of the Brains.
-
Documental de BBC Radio llamado Analysis on Artificial Intelligence.
-
Documentales de la serie Through the Wormhole: Is There Life After Death?, Can Our Minds Be Hacked?, Are Robots the Future of Human Evolution? y Do We Have Free Will?.
Referencias
[1] ABC, “Neymar’s brain on auto-pilot when playing for Brazil and Barcelona: neurologists,” 2014. [http://www.abc.net.au/news/2014-07-25/neymar-brain-on-auto-pilot/5625056, En línea; accedido el 19-Junio-2015].
[2] Stanford University News Service, “Collective intelligence: Ants and brain’s neurons,” 1993. [http://news.stanford.edu/pr/93/931115Arc3062.html, En línea; accedido el 20-Junio-2015].
[3] U. of Sussex, “Francis Ratnieks,” 2015. [http://www.sussex.ac.uk/profiles/128567, En línea; accedido el 20-Junio-2015].
[4] S. Coren, “Which Emotions Do Dogs Actually Experience?,” 2015. [http://moderndogmagazine.com/articles/which-emotions-do-dogs-actually-experience/32883, En línea; accedido el 20-Junio-2015].
[5] Wikipedia, “Intelligence — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 20-June-2015].
[6] Wikipedia, “Nootropic — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 20-June-2015].
[7] Wikipedia, “Artificial intelligence — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 20-June-2015].
[8] Wikipedia, “Discipline (academia) — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 27-June-2015].
[9] S. McGrayne, The Theory that Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, & Emerged Triumphant from Two Centuries of Controversy. Yale University Press, 2011.
[10] N. J. Nilsson, The Quest for Artificial Intelligence. New York, NY, USA: Cambridge University Press, 1st ed., 2009.
[11] Wikipedia, “Cybernetics — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 28-June-2015].
[12] Wikipedia, “Neuroscience — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 28-June-2015].
[13] M. Velliste, S. Perel, M. C. Spalding, A. S. Whitford, and A. B. Schwartz, “Cortical control of a prosthetic arm for self-feeding,” Nature, vol. 453, pp. 1098–1101, 06 2008.
[14] Wikipedia, “Cognitive science — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 28-June-2015].
[15] S. Kirby, H. Cornish, and K. Smith, “Cumulative cultural evolution in the laboratory: An experimental approach to the origins of structure in human language,” Proceedings of the National Academy of Sciences, vol. 105, no. 31, pp. 10681–10686, 2008.
[16] P. Dayan and L. F. Abbott, Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems. The MIT Press, 2005.
[17] J. Hawkins and S. Blakeslee, On Intelligence. Henry Holt and Company, 2007.
[18] N. Danaylov, “Marvin Minsky on Singularity 1 on 1: The Turing Test is a Joke!,” 2013. [Online; accessed 28-June-2015].
[19] IBM, “Deep Blue,” 2015. [Online; accessed 28-June-2015].
[20] I. Research, “How Deep Blue Works,” 2015. [Online; accessed 28-June-2015].
[21] T. A. James Somers, “The Man Who Would Teach Machines to Think,” 2013. [Online; accessed 28-June-2015].
[22] S. J. Russell and P. Norvig, Artificial Intelligence: A Modern Approach. Pearson Education, 2 ed., 2003.
[23] P. Norvig, “On Chomsky and the Two Cultures of Statistical Learning,” 2012. [Online; accessed 28-June-2015].
[24] T. A. Yarden Katz, “Noam Chomsky on Where Artificial Intelligence Went Wrong,” 2012. [Online; accessed 28-June-2015].
[25] M. Minsky, “Emotion Machine: Commonsense Thinking, Artificial Intelligence, and the Future of the Human Mind,” 2011. [Online; accessed 28-June-2015].
[26] M. L. Minsky and S. Papert, Perceptrons: An Introduction to Computational Geometry. Cambridge Mass.: MIT Press, expanded ed., 1969.
[27] S. Papert, “One ai or many?,” in The Artificial Intelligence Debate: False Starts, Real Foundations (S. R. Graubard, ed.), pp. 11–14, Cambridge, MA: MIT Press, 1989.
[28] T. M. Mitchell, Machine Learning. WCB McGraw-Hill, 1997.
[29] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf, “DeepFace: Closing the Gap to Human-Level Performance in Face Verification,” June 2014.
[30] M. Lichman, “UCI Machine Learning Repository,” 2013.
[31] A. Ng, “Lecture 4 - Unsupervised Learning,” 2015. [Online; accessed 4-July-2015].
[32] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, pp. 529–533, 02 2015.
[33] Wikipedia, “Hebbian theory — Wikipedia, The Free Encyclopedia,” 2015. [Online; accessed 5-July-2015].
[34] P. J. Werbos, “Tutorials: From Neural Networks to the Intelligent Power Grid: What it Takes to Make Things Work,” in Industrial Electronics Society, 2005. IECON 2005. 31st Annual Conference of IEEE, pp. 18–22, Nov 2005.
[35] J. Schmidhuber, “Who Invented Backpropagation?,” 2015. [http://people.idsia.ch/~juergen/who-invented-backpropagation.html, En línea; accedido el 22-Julio-2015].
[36] J. Anderson and E. Rosenfeld, Talking Nets: An Oral History of Neural Networks. Bradford Books, MIT Press, 2000.
[37] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,” Nature, vol. 323, pp. 533–536, 10 1986.
[38] Y. Bengio, I. J. Goodfellow, and A. Courville, “Deep Learning.” Book in preparation for MIT Press, 2015.
[39] Y. Bengio, “Learning Deep Architectures for AI,” Foundations and Trends® in Machine Learning, vol. 2, no. 1, pp. 1–127, 2009.
[40] N. Jones, “Computer Science: The Learning Machines,” Nature, vol.505, pp. 146–148, jan 2014.
[41] B. Poczos and A. Singh, “Introduction to machine learning - deep learning.” University Lecture, 2014.
[42] A. Rubinsteyn, “NIPS and the Zuckerberg Visit,” 2013. [http://blog.explainmydata.com/2013/12/nips-and-zuckerberg-visit.html, En línea; accedido el 26-Julio-2015].
[43] J. O’Callaghan, “Meet the robot BUILDER: Fully automated bricklaying machine can create an entire house in just two days,” 2015. [http://www.dailymail.co.uk/sciencetech/article-3140546/Meet-robot-BUILDER-Fully-automated-bricklaying-machine-create-entire-house-just-two-days.html, En línea; accedido el 26-Julio-2015].
[44] B. R. . Analysis, “Artificial Intelligence,” 2015. [http://www.bbc.co.uk/programmes/b05372sx, En línea; accedido el 26-Julio-2015].
[45] S. Lohr, “I.B.M.’s Watson Goes to Medical School,” 2021. [http://bits.blogs.nytimes.com/2012/10/30/i-b-m-s-watson-goes-to-medical-school/, En línea; accedido el 26-Julio-2015].
[46] W. S. Swanson, “Have You Been In To See Dr. Google?,” 2015. [http://seattlemamadoc.seattlechildrens.org/have-you-been-in-to-see-dr-google/, En línea; accedido el 26-Julio-2015].
[47] A. North, “A ‘Star Trek’ Future Might Be Closer Than We Think,” 2015. [http://takingnote.blogs.nytimes.com/2015/07/10/a-star-trek-future-might-be-closer-than-we-think/, En línea; accedido el 26-Julio-2015].
[48] R. Cellan-Jones, “Stephen Hawking warns artificial intelligence could end mankind,” 2015. [http://www.bbc.com/news/technology-30290540, En línea; accedido el 27-Julio-2015].
[49] C. Williams, “AI guru Ng: Fearing a rise of killer robots is like worrying about overpopulation on Mars,” 2015. [http://www.theregister.co.uk/2015/03/19/andrew_ng_baidu_ai/, En línea; accedido el 27-Julio-2015].
[50] S. Connor, “Stephen Hawking right about dangers of AI… but for the wrong reasons, says eminent computer expert,” 2015. [http://www.independent.co.uk/news/science/stephen-hawking-right-about-dangers-of-ai-but-for-the-wrong-reasons-says-eminent-computer-expert-9908450.html, En línea; accedido el 27-Julio-2015].
[51] P. Ford, “Our Fear of Artificial Intelligence,” 2015. [http://www.technologyreview.com/review/534871/our-fear-of-artificial-intelligence/, En línea; accedido el 27-Julio-2015].
[52] N. Bostrom, Superintelligence: Paths, Dangers, Strategies. Oxford University Press, 2014.
[53] T. G. Dietterich, “Benefits and Risks of Artificial Intelligence,” 2015. [https://medium.com/@tdietterich/benefits-and-risks-of-artificial-intelligence-460d288cccf3, En línea; accedido el 28-Julio-2015].
[54] S. Turkle, Alone Together: Why We Expect More from Technology and Less from Each Other. Basic Books, 2011.
[55] S. Gibbs, “Musk, Wozniak and Hawking urge ban on warfare AI and autonomous weapons,” 2015. [http://www.theguardian.com/technology/2015/jul/27/musk-wozniak-hawking-ban-ai-autonomous-weapons, En línea; accedido el 28-Julio-2015].
[56] R. Hof, “Now, Even Artificial Intelligence Gurus Fret That AI Will Steal Our Jobs,” 2015. [http://www.forbes.com/sites/roberthof/2015/01/31/now-even-artificial-intelligence-gurus-fret-that-ai-will-steal-our-jobs/, En línea; accedido el 28-Julio-2015].
-
Una crítica sobre la clasificación y especialización de las disciplinas y jerarquización y descalificación de individuos respecto a ellas las hace Michel Foucault en su libro Disciplina y Castigo[8]. ↩
-
Cabe mencionar que uno de los pioneros de la Cibernética fue el Médico mexicano Arturo Rosenblueth Stearns. ↩
-
Cabe aclarar que tanto la ‘ciencia’ de datos como la ‘ciencia’ de la computación no son ciencias. Para empezar, la Ciencia sólo es una y no muchas y abarca todo el conocimiento sistemático. En el caso de la ‘ciencia’ de datos, su estudio ya había sido ocupado por la estadística. En cuanto a las ‘ciencias’ de la computación, a su estudio se basa en teoría matemáticas como la de la Información y de la Computabilidad, por lo que es parte de las matemáticas. ↩
-
Este experimento esta reseñado en el capítulo Why Do We Talk? de 2009 de la serie de documentales de la BBC Horizon ↩
-
Disponible gratuitamente en https://www.princeton.edu/ hos/h598/papert.daedalus.pdf. ↩
-
La demostración matemática de esto se le conoce como el teorema del No-Free Lunch. ↩
-
Un video del resultado de este aprendizaje se encuentra en https://www.youtube.com/watch?v=iqXKQf2BOSE. ↩
-
Recientemente, investigadores suecos crearon neuronas artificiales capaces de conectarse con las orgánicas (ver más en http://www.kurzweilai.net/swedish-scientists-create-an-artificial-neuron-that-mimicks-an-organic-one). ↩
-
El perceptron no es el único modelo matemático que se basa en la ley de Hebb. Un modelo más fiel a la ley de Hebb es la red de Hopefield, la cual reavivó el estudio de las redes neuronales durante los ochenta. ↩
-
Esta es una versión del clásico problema de clasificación de una función binaria XOR presentado en [26]. ↩
-
Para ver más acerca de esto ver el teorema de aproximación universal de Kolmogorov. ↩
-
Un ejemplo de que el avance científico estable depende de tecnología común, en este caso proveniente de la industria de los videojuegos. ↩
-
Aunque en un mundo en el que todo trabajo está automatizado y, en consecuencia, las necesidades son cubiertas gratuitamente, el trabajo no dejaría de existir. Lo que sí dejaría de existir es el dinero y su uso como símbolo de estatus. El éxito probablemente sería medido respecto a logros [47]. ↩
-
Quién estuvo casada con Seymour Papert. ↩