Randomly Sampling Cells From a Grid With a Hole
This post covers how to random and efficiently sample cells from a grid with a hole. This is useful when you would like to avoid square regions in images. The problem consists in choosing any cell from a matrix grid avoiding a squared region within it. The problem is illustrated in the image below, where only the blue cells from a grid of 6x6 can randomly be picked up.
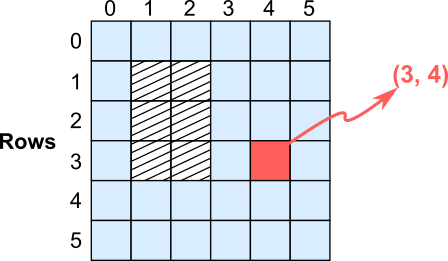
The easy solution is to randomly sample the rows and columns from two discrete uniform distributions and check if they are outside the squared region. If they are inside, then we recalculate both subscripts again. In the example above, the subscripts \((x,y)\) are defined as:
\[\begin{eqnarray} x=\mathcal{U}\{0, r-1\}\\ y=\mathcal{U}\{0, c-1\} \end{eqnarray}\]where \(r=6\) and \(c=6\) are the number of rows and columns in the grid.
The first thing to notice is that we can use flat or linear indices mapping to just make one random sampling. When there are no sampling restrictions, the indices look like this:
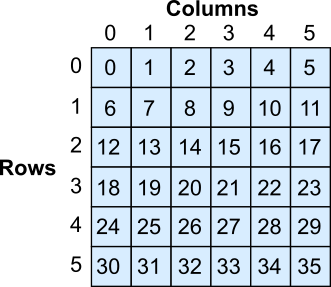
In this case, the solution is defined as:
\[\begin{eqnarray} f=\mathcal{U}\{0, r\cdot c-1\}\\ \end{eqnarray}\]and we map the linear indices to subscripts by
\[\begin{eqnarray} x=f\: \text{div}\: c\\ y=f\: \text{mod}\: c \end{eqnarray}\]If we add the squared region and remove the rows and columns subscripts to our linear indices grid, then the problem looks like this:
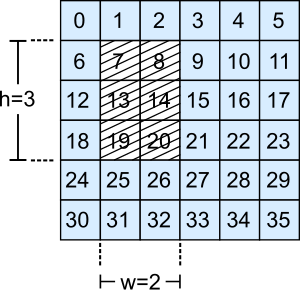
where \(h\) and \(w\) are the height and width of the squared area. The second step to our solution is to sample the correct number of cells by defining \(n=\mathcal{U}\{0, r\cdot c-w\cdot h-1\}\). In our example, we are no longer sampling 36 numbers but 30, so \(n=\mathcal{U}\{0, 29\}\).
Since the random number \(n\) does not cover all the cell indices, is necessary to define the function \(s(n)\) as the number of cells to slide. So we define \(f(n)=n+s(n)\). Continuing with our example, randomly sampling the number 15 can be seen as:

Also notice from the above figure that the set of flat indices \(\{7, 8, 13, 14, 19, 20\}\) are not part of function \(f(n)\).
The last step is to define \(s(n)\), in order to mathematically define it, we need a closer look into it. Our observations about its behavior are summarized in the following figure:
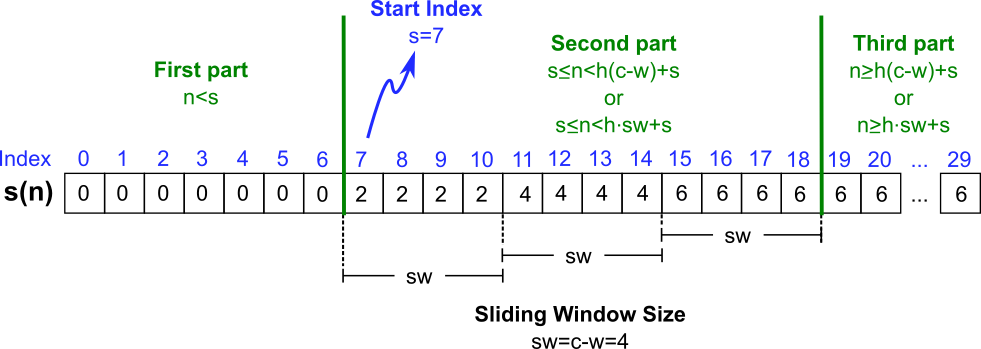
First, we notice that \(s(n)\) is a piecewise function defined by three parts. We can also notice that the values for the first and last parts are trivially known and correspond to 0 and \(w\cdot h\). The middle part is more interesting as it has loop mechanism, that can be seen as the following:
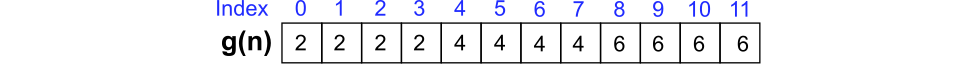
and define as \(g(n) = w\cdot(1+n\,\text{div}\,sw)\). Putting all together, our solution is the following:
\[n=\mathcal{U}\{0,r\cdot c-w\cdot h-1\}\\[10pt]\] \[s(n) = \begin{cases} 0 &\quad\text{if}\quad n<s\\[10pt] w\cdot(1+(n-s)\quad\text{div}\quad sw) &\quad \text{if}\quad s\leq n<(h-1)\cdot sw+s\\[10pt] w\cdot h &\quad \text{otherwise} \\[10pt] \end{cases}\\[10pt]\] \[\begin{eqnarray} f(n)=n+s(n)\\[10pt] \end{eqnarray}\]and
\[\begin{eqnarray} x=f(n)\: \text{div}\: c\\ y=f(n)\: \text{mod}\: c \end{eqnarray}\]Notice that the slight adjustment made to the domain of the middle part of \(s(n)\) makes it more optimal.